
DragOn: Benchmark y dataset para interacciones GUI con arrastre
Mejora el grounding de arrastre en asistentes GUI con DragOn: 3.5M tareas de resalte, selección y más. Benchmark y dataset para entrenar modelos de IA.
Mejora el grounding de arrastre en asistentes GUI con DragOn: 3.5M tareas de resalte, selección y más. Benchmark y dataset para entrenar modelos de IA.

Nuevo benchmark CausalPhys con 3,000 preguntas evalúa razonamiento causal en VLMs. Mejora precisión e interpretabilidad con aprendizaje causal.

Descubre cómo DRIFT adapta modelos de visión-lenguaje para generar salidas continuas con precisión, mejorando tareas como grounding visual y control robótico.
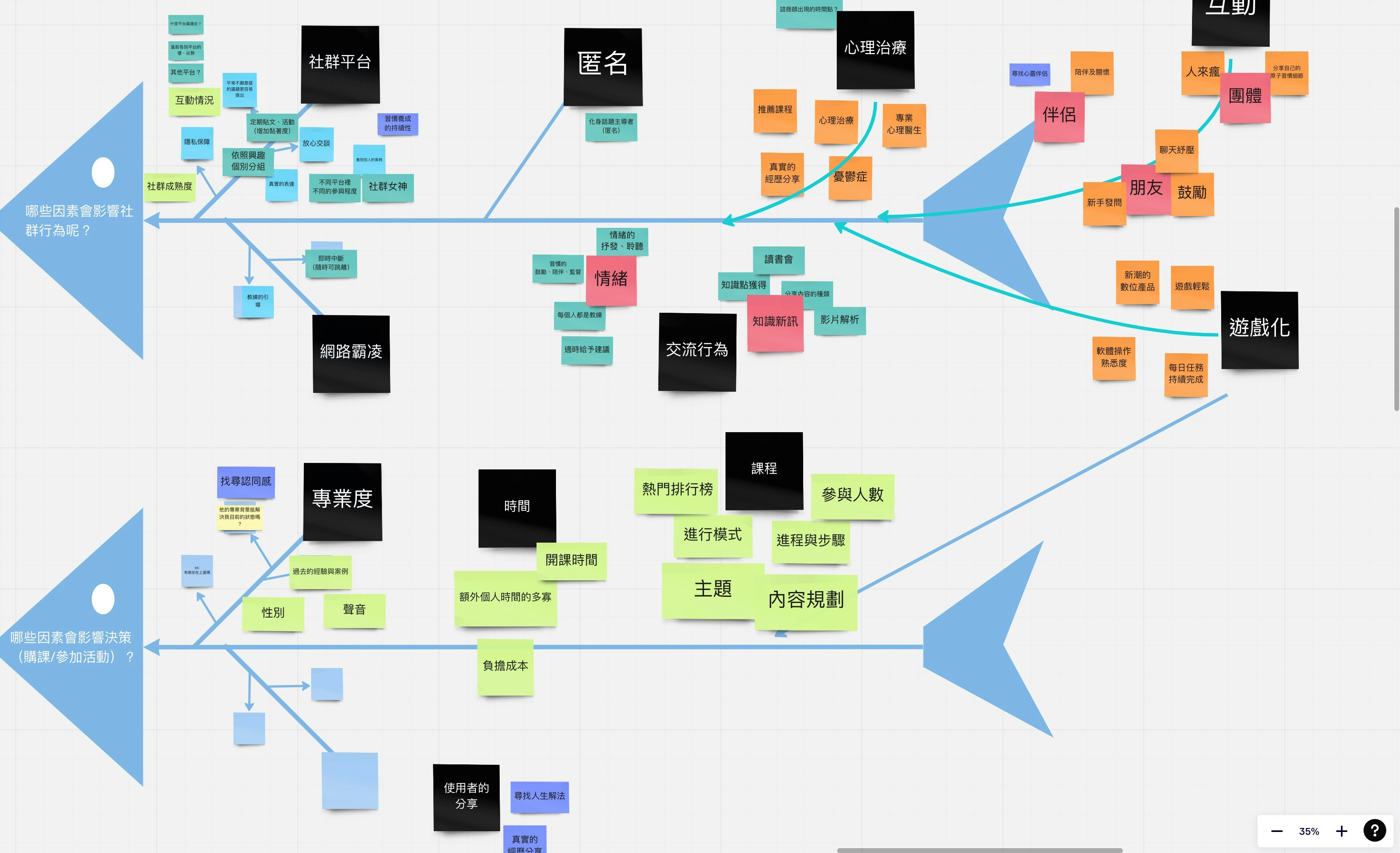
DRIFT adapta modelos VLM para salidas continuas con un adaptador de flujo residual, mejorando precisión en percepción y control robótico.

Descubre cómo LEVANTE-bench compara modelos de IA con niños de 5 a 12 años en tareas cognitivas. ¿Son los VLMs más inteligentes que un niño de 5º grado?

EvoPrompt: evolución guiada de prompts para adaptación sin olvido de VLMs en pocos datos. Preserva conocimiento pre-entrenado.

Codificadores visuales con estado mejoran la comparación entre imágenes en modelos de visión-lenguaje, superando a especialistas en radiología y teledetección.

Descubre cómo los codificadores visuales con estado mejoran los modelos visión-lenguaje en tareas multi-imagen y superan a modelos en radiología y teledetección

SAS revela asimetrías en modelos visión-lenguaje médicos, midiendo desequilibrio de modalidad. Útil para diagnóstico práctico en IA clínica.

KODA compara y alinea representaciones de modelos visión-lenguaje como CLIP y SigLIP usando kernels. Identifica discrepancias estructurales interpretables.

Descubre cómo OGKD mejora la precisión en modelos médicos al respetar relaciones entre clases. Resultados superiores en 11 datasets.

Descubre cómo medir el rol de cada codificador en modelos VLM multicodificador. Capacidad y Necesidad revelan pares óptimos para entrenar sin acumular. Investigación con 16 benchmarks.
Descubre Align-KD, técnica que destila conocimiento de alineación multimodal de VLMs grandes a modelos móviles, mejorando precisión en 6 benchmarks.
Descubre BYORn, método que protege modelos visión-lenguaje durante fine-tuning contra ataques backdoor, mejorando robustez.

PolarMem: sistema de memoria gráfica polarizada sin entrenamiento que verifica y reduce contradicciones en modelos de visión-lenguaje para un razonamiento multimodal confiable.

StreamingVLM revoluciona la comprensión de video en tiempo real: procesa flujos infinitos con solo 8 FPS en un H100, superando a GPT-4O mini. ¡Descubre su arquitectura!
CARES es un módulo ligero que selecciona la resolución mínima para VLMs, reduciendo el cómputo hasta un 80% sin perder precisión. Optimiza tus modelos.

Los distractores visuales afectan a los modelos visión-lenguaje de forma distinta a los textuales: reducen precisión sin alargar el razonamiento. Aprende a mitigarlos.

DeepLatent: revolucionario marco paralelo de razonamiento visual latente. Usa tokens 2D y RL continuo para alcanzar rendimiento de vanguardia en benchmarks clave.

Descubre cómo DAT corrige correlaciones espurias en VLMs zero-shot usando densidad local para mejorar precisión sin ajuste fino.